
PostgreSQL, also known as Postgres, is a free and open-source relational database management system emphasizing extensibility and SQL compliance.
Overview
Hightouch lets you pull data stored in your PostgreSQL database and push it to downstream destinations. Most of the setup occurs in the Hightouch UI, but you need access to your PostgreSQL instance for information like your host, port, database name, and credentials.
You may need to allowlist Hightouch's IP addresses to let our systems connect to your Postgres instance. Reference our networking docs to determine which IP addresses you need to allowlist.
You can also securely connect to your Postgres instance using AWS PrivateLink or GCP Private Service Connect. AWS PrivateLink and GCP Private Service Connect are Business Tier features.
Connection configuration
Hightouch officially supports PostgreSQL versions 15 and above. While some features may still work with earlier versions, compatibility isn’t guaranteed, and future updates might introduce changes affecting older versions.
To get started, go to the Sources overview page and click the Add source button. Select PostgreSQL and follow the steps below.
Choose connection type
Hightouch can connect directly to PostgreSQL over the public internet or via an SSH tunnel. Since data is encrypted in transit via TLS, a direct connection is suitable for most use cases. You may need to set up a tunnel if your PostgreSQL instance is on a private network or virtual private cloud (VPC).
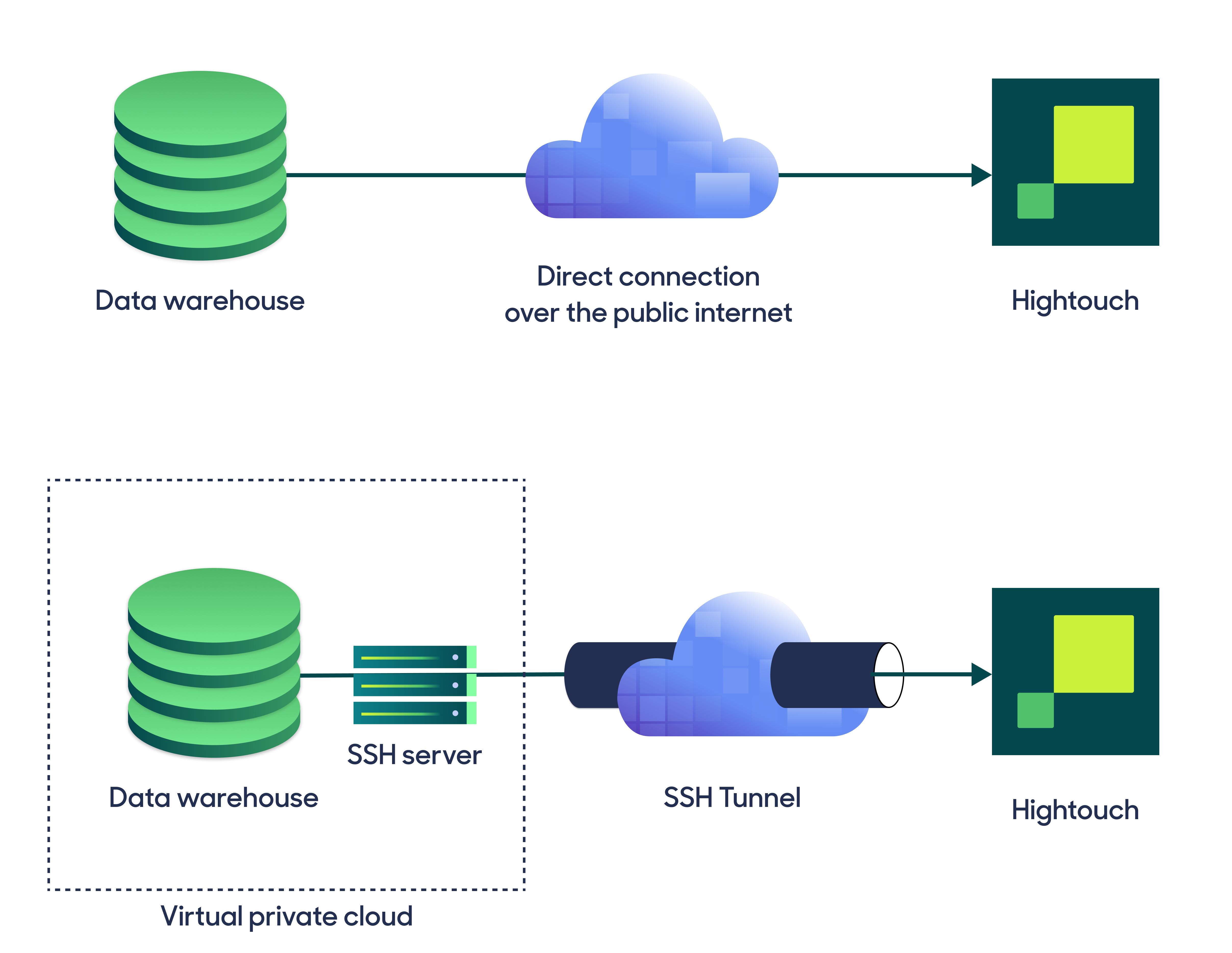
Hightouch supports both standard and reverse SSH tunnels. To learn more about SSH tunneling, refer to Hightouch's tunneling documentation.
Configure your source
Enter the following required fields into Hightouch:
- Host: The hostname or IP address of your PostgreSQL server.
- Port: The port number of your PostgreSQL server. The default port number is 5432, but yours may be different.
- Database: This specifies the database to use when Hightouch executes queries in PostgreSQL.
Choose your sync engine
For optimal performance, Hightouch tracks incremental changes in your data model—such as added, changed, or removed rows—and only syncs those records. You can choose between two different sync engines for this work.
The Basic engine requires read-only access to PostgreSQL. Hightouch executes a query in your database, reads all query results, and then determines incremental changes using Hightouch's infrastructure. This engine is easier to set up since it requires read—not write—access to PostgreSQL.
The Lightning engine requires read and write access to PostgreSQL. The engine stores previously synced data in a separate schema in PostgreSQL managed by Hightouch. In other words, the engine uses PostgreSQL to track incremental changes to your data rather than performing these calculations in Hightouch. Therefore, these computations are completed more quickly.
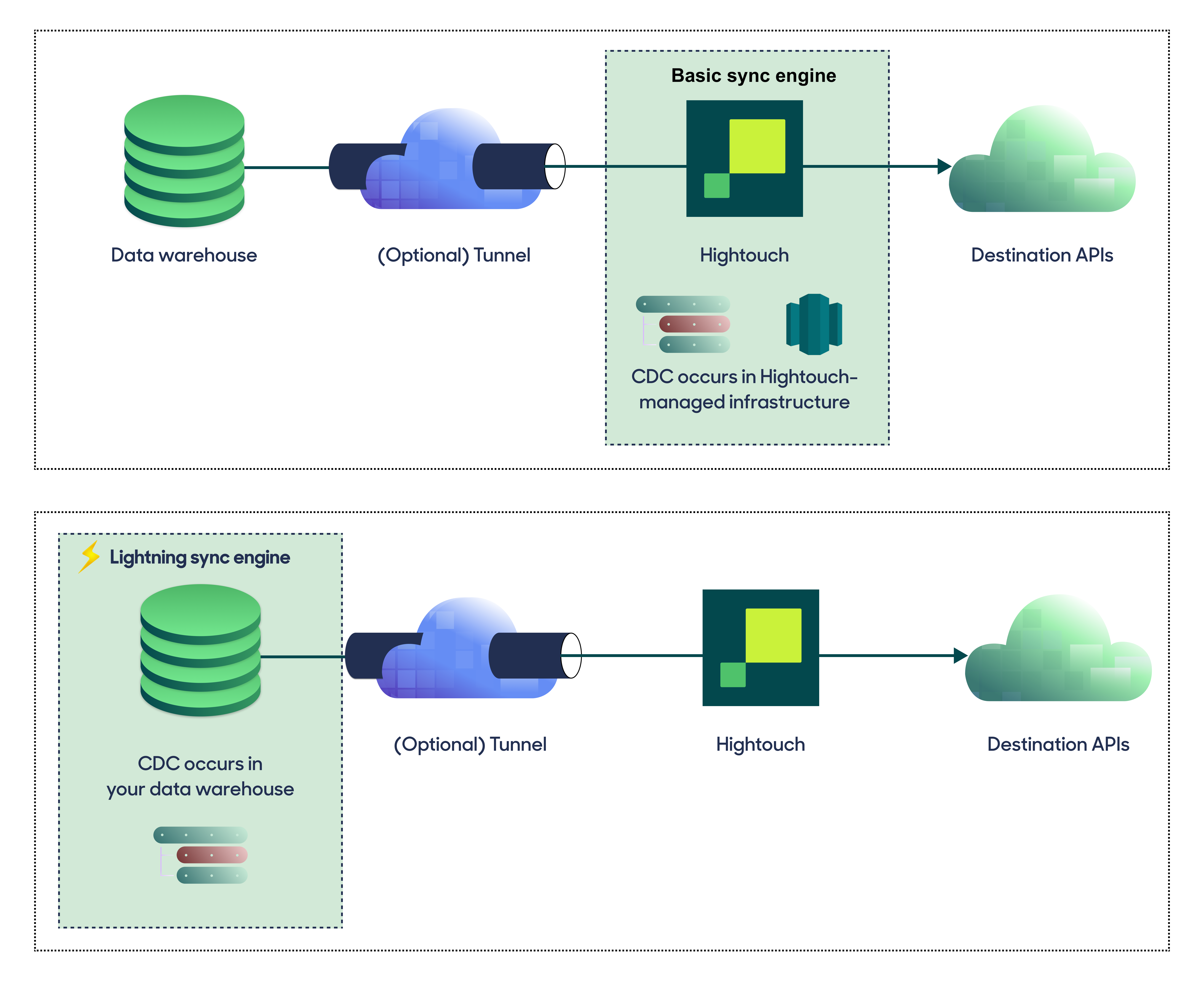
If you select the Basic engine, you can switch to the Lightning engine later. Once you've configured the Lightning engine, you can't move back to the Basic engine without recreating PostgreSQL as a source.
To learn more, including migration steps and tips, check out the Lightning sync engine docs.
Basic versus Lightning engine comparison
The Lightning sync engine requires granting write access to your data warehouse, which makes its setup more involved than the Basic sync engine. However, it is more performant and reliable than the Basic engine. This makes it the ideal choice to guarantee faster syncs, especially with large data models. It also supports more features, such as Warehouse Sync Logs, Match Booster, and Identity Resolution.
| Criteria | Basic sync engine | Lightning sync engine |
|---|---|---|
| Performance | Slower | Quicker |
| Ideal for large data models (over 100 thousand rows) | No | Yes |
| Reliability | Normal | High |
| Resilience to sync interruptions | Normal | High |
| Extra features | None | Warehouse Sync Logs, Match Booster, Identity Resolution |
| Ease of setup | Simpler | More involved |
| Location of change data capture | Hightouch infrastructure | PostgreSQL schemas managed by Hightouch |
| Required permissions in PostgreSQL | Read-only | Read and write |
| Ability to switch | You can move to the Lightning engine at any time | You can't move to the Basic engine once Lightning is configured |
Lightning engine setup
To set up the Lightning engine, you need to grant Hightouch write access to PostgreSQL. You can do so by running the following SQL snippet.
CREATE USER hightouch_user WITH PASSWORD '********';
CREATE SCHEMA IF NOT EXISTS hightouch_audit;
CREATE SCHEMA IF NOT EXISTS hightouch_planner;
GRANT CREATE, USAGE ON SCHEMA hightouch_audit TO hightouch_user;
GRANT CREATE, USAGE ON SCHEMA hightouch_planner TO hightouch_user;
The snippet creates a dedicated PostgreSQL user for Hightouch. It also provisions two schemas (hightouch_planner and hightouch_audit) for storing logs of previously synced data.
Provide credentials
Enter the following fields into Hightouch:
- User: This can be your personal PostgreSQL login or a dedicated user for Hightouch. At minimum, this user must have read access to the data you wish to sync. If using the Lightning sync engine, you must also grant this user additional permissions as described above.
- Password: The password for the user specified above.
Test your connection
When setting up a source for the first time, Hightouch validates the following:
- Network connectivity
- PostgreSQL credentials
- Permission to list schemas and tables
- Permission to write to
hightouch_plannerschema - Permission to write to
hightouch_auditschema
All configurations must pass the first three, while those with the Lightning engine must pass all of them.
Some sources may initially fail connection tests due to timeouts. Once a connection is established, subsequent API requests should happen more quickly, so it's best to retry tests if they first fail. You can do this by clicking Test again.
If you've retried the tests and verified your credentials are correct but the tests are still failing, don't hesitate to .
Next steps
Once your source configuration has passed the necessary validation, your source setup is complete. Next, you can set up models to define which data you want to pull from PostgreSQL.
The PostgreSQL source supports these modeling methods:
- writing a query in the SQL editor
- using the visual table selector
- leveraging existing dbt models
- leveraging existing Looker Looks
- leveraging existing Sigma workbooks
You may also want to consider storing sync logs in PostgreSQL. Like using the Lightning sync engine versus the standard one, this feature lets you use PostgreSQL instead of Hightouch infrastructure. Rather than performance gains, it makes your sync log data available for more complex analysis. Refer to the warehouse sync logs docs to learn more.
You must enable the Lightning sync engine to store sync logs in your warehouse.
Tips and troubleshooting
If you encounter an error or question not listed below and need assistance, don't hesitate to . We're here to help.
Canceling statement due to statement timeout
This error occurs when the required execution time of your PostgreSQL query exceeds the timeout limit for the database. To address the error, increase the timeout by executing the following query:
set statement_timeout = '300 s'; -- 300 seconds, 5 minutes
Be sure to adjust the time to be as long as it takes for your query to execute.
Terminating connection due to conflict with recovery
This error can happen if the max_standby_archive_delay and max_standby_streaming_delay values in your PostgreSQL configuration are too low. Try increasing them as suggested in the AWS Knowledge Center.